
I’ve long been a fan of minimal game runtimes. Anything that can be done offline or in a separate tool, should be out of the runtime. That leaves the game architecture and code very lean and simple.
One of the things you potentially give up by keeping the game runtime to a minimum is an editor built in the game itself. But that’s one of those things that sounds a lot better than it really is. From a technical point of view, having an editor in the game usually complicates the code a huge amount. All of a sudden you need to deal with objects being created and destroyed randomly (instead of through clearly defined events in the game), and you have to deal with all sorts of crazy inputs and configurations.
The worse part though, is having to implement some sort of GUI editing system in every platform. Creating the GUI to run on top of the game is not easy, requiring that you create custom GUI code or try to use some of the OpenGL/DirectX libraries available. And even then, a complex in-game GUI might not be a big deal on a PC, but wait and try to use that interface on a PS3 or iPhone. After all, making games is already complicated and time-consuming enough to waste more time reinventing the widget wheel.
Remote game editing manages to keep a minimal runtime and allow you to quickly create native GUIs that run on a PC. It’s the best of both worlds, and although it’s not quite a perfect solution, it’s the best approach I know.
Debug Server
Miguel Ãngel Friginal already covered the basics of the debug server, so I’m not going to get in details there.
The idea is that you run a very simple socket server on the game, listening in a particular port. This server implements the basic telnet protocol, which pretty much means that it’s a line-based, plain-text communication.
The main difference between my debug server and Miguel’s (other than mine is written in cross-platform C/C++ instead of ObjC), is that I’m not using Lua to execute commands. Using Lua for that purpose is a pretty great idea, but goes against the philosophy of keeping the runtime as lean and mean as possible.
Instead, I register variables with the server by hand. For each variable, I specify its memory address, it’s type, any restrictions (such as minimum and maximum values), and a “pretty name” to display in the client. Sounds like a lot of work, but it’s just one line with the help of a template:
registry.Add(Tweak(&plantOptions.renderGloss, "render/gloss", "Render gloss")); registry.Add(Tweak(&BouquetParams::FovY, "bouquet/fov", "FOV", Pi/32, Pi/3))
And yes, if I were to implement this today, I would probably get rid of the templates and make it all explicit instead (ah, the follies of youth 🙂
TweakUtils::AddBool(registry, &plantOptions.renderGloss, "render/gloss", "Render gloss"); TweakUtils::AddFloat(registry, &BouquetParams::FovY, "bouquet/fov", "FOV", Pi/32, Pi/3);
The debug server itself responds to three simple commands:
- list. Lists all the variables registered in the server.
- set varname value. Sets a value.
- print varname. Gets the value for that variable.
For example, whenever the server receives a set command, it parses the value, verifies that it’s within the acceptable range, and applies it to the variable at the given memory location.
Telnet Clients
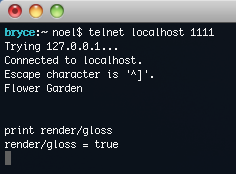 Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.
Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.
However, most telnet clients leave much to be desired for this. They all rely on the history and cursor manipulation being handled by the shell they assume you’re connected to. Here we aren’t connected to much of anything, but I’d like to be able to push up arrow and get my last command, and be able to move to the beginning of the line or the previous word like I would do in any text editor. The easiest solution I found for that was to use a telnet client prepared for that kind of thing: A MUD client! Just about any will do, but one that works well for me is Atlantis.
So far, we’ve implemented the equivalent of a FPS console, but working remotely. And because the code is fully portable, our game can be in just about any platform and we can always access it from our PC. Not just that, but we can even open multiple simultaneous connections to various development devices if you need to run them all at once.
Custom Clients
Game parameter tweaking is something that is OK through a text-based console, but really comes into its own when you add a GUI. That’s exactly what we did at Power of Two Games. We created a generic GUI tool (based on WinForms since we were on Windows at the time), that would connect to the server, ask for a list of variables, and generate a GUI on the fly to represent those variables. Since we knew type and name of each variable, it was really easy to construct the GUI elements on the fly: A slider with a text field for floats and ints, a checkbox for bools, four text fields for vectors, and even a color picker for variables of the type color.
It worked beautifully, and adjusting different values by moving sliders around was fantastic. We quickly ran into two problems through.
The first one is that we added so many different tweaks to the game, that it quickly became unmanageable to find each one we wanted to tweak. So, in the spirit of keeping things as simple as possible (and pushing the complexity onto the client), we decided that the / symbol in a name would separate group name and variable name. That way we could group all related variables together and make everything usable again.
The second problem was realizing that some variables were changing on the runtime without us knowing it on the client. That created weird situations when moving sliders around. We decided that any time a registed variable changes on the server, it should notify any connected clients. That worked fine, but, as you can imagine, it became prohibitively expensive very quickly. To get around that, we added a fourth command: monitor varname. This way clients need to explicitly register themselves to receive notifications whenever a variable changes, and the GUI client only did it for the variables currently displayed on the screen.
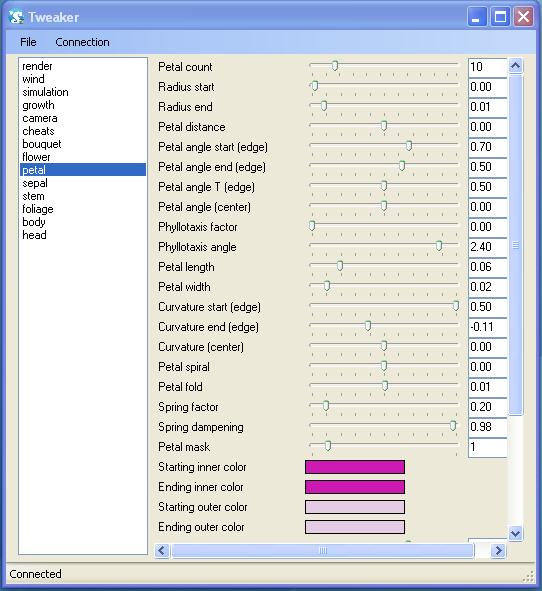
During this process, it was extremely useful to be able to display a log console to see what kind of traffic there was going back and forth. It helped me track down a few instances of bugs where changing a variable in the client would update it in the server, sending an update back to the client, which would send it again back to the server, getting stuck in an infinite loop.
You don’t need to stop at a totally generic tool like this either. You could create a more custom tool, like a level editor, that still communicates with the runtime through this channel.
Flower Garden Example
For Flower Garden, I knew I was going to need a lot of knobs to tweak all those plant DNA parameters, so I initially looked into more traditional GUI libraries that worked on OpenGL. The sad truth is that they all fell way short, even for development purposes. So I decided to grab what I had at hand: My trusty tweaking system from Power of Two Games.
I’m glad I did. It saved a lot of time and scaled pretty well to deal with the hundreds of parameters in an individual flower, as well as the miscellaneous tweaks for the game itself (rendering settings, infinite fertilizer, fast-forwarding time, etc).
Unfortunately, there was one very annoying thing: The tweaker GUI was written in .Net. Sure, it would take me a couple of days to re-write it in Cocoa (faster if I actually knew any Cocoa), but as an indie, I never feel I can take two days to do something tangential like that. So instead, I just launched it from VMWare Fusion running Windows XP and… it worked. Amazingly enough, I’m able to connect from the tweaker running in VMWare Fusion to the iPhone running in the simulator. Kind of mind boggling when you stop and think about it. It also connects directly to the iPhone hardware without a problem.
VMWare Fusion uses up a lot of memory, so I briefly looked into running the tweaker client in Mono. Unfortunately Mono for the Mac didn’t seem mature enough to handle it, and not only was the rendering of the GUI not refreshing correctly, but events were triggered in a slightly different order than in Windows, causing even more chaos with the variable updates.
Here’s a time-lapse video of the creation of a Flower Garden seed from the tweaker:
Drawbacks
As I mentioned earlier, I love this system and it’s better than anything else I’ve tried, but it’s not without its share of problems.
Tweaking data is great, but once you find that set of values that balances the level to perfection… then what? You write those numbers down and enter them in code or in the level data file? That gets old fast. Ideally you want a way to automatically write those values back. That’s easy if the tool itself is the editor, but if it’s just a generic tweaker, it’s a bit more difficult.
One thing that helped was adding a Save/Load feature to the tweaker GUI. It would simply write out a large text-based file with all the variables and their current values. Whenever you load one of those, it would attempt to apply those same values to the current registered variables. In the end, I ended up making the Flower Garden offline seed file format match with what the tweaker saved out, so that process went pretty smoothly.
Another problem is if you want lots of real-time (or close to real time) updates from the server. For example, you might want to monitor a bunch of data points and plot them on the client (fps, memory usage, number of collisions per frame, etc). Since those values change every frame, it can quickly overwhelm the simple text channel. For those cases, I created side binary socket channels that can simply send real-time data without any overhead.
Finally, the last drawback is that this tweaking system makes editing variables very easy, but calling functions is not quite as simple. For the most part, I’ve learned to live without function calls, but sometimes you really want to do it. You can extend the server to register function pointers and map those to buttons in the client GUI, but that will only work for functions without any parameters. What if you wanted to call any arbitrary function? At that point you might be better off integrating Lua in your server.
Future Directions
This is a topic I’ve been interested in for a long time, but the current implementation of the system I’m using was written 3-4 years ago. As you all know by now, my coding style and programming philosophy changes quite a bit over time. If I were to implement a system like this today, I would do it quite differently.
For all I said about keeping the server lean and minimal, it could be even more minimal. Right now the server is receiving text commands, parsing them, validating them, and interpreting them. Instead, I would push all that work on the client, and all the server would receive would be a memory address, and some data to blast at that location. All of that information would be sent in binary (not text) format over a socket channel, so it would be much more efficient too. The only drawback is that we would lose the ability to connect with a simple telnet client, but it would probably be worth it in the long run.
This post is part of iDevBlogADay, a group of indie iPhone development blogs featuring two posts per day. You can keep up with iDevBlogADay through the web site, RSS feed, or Twitter.

 Apparently I’m not a total Const Nazi because this is one possible use of const that I choose to skip (even though I tried it for a while because of
Apparently I’m not a total Const Nazi because this is one possible use of const that I choose to skip (even though I tried it for a while because of 


 By giving up on TDD for high-level code, you’ll be missing out on the main benefit of TDD: designing better code. I’ve said this many times, but it bears repeating: TDD is not a testing technique. It’s a design technique. You get lots of benefits from applying TDD
By giving up on TDD for high-level code, you’ll be missing out on the main benefit of TDD: designing better code. I’ve said this many times, but it bears repeating: TDD is not a testing technique. It’s a design technique. You get lots of benefits from applying TDD