
Anybody who worked with me or saw any of my code, would know right away why they call me the Const Nazi. That’s because in my coding style, I make use of the keyword const everywhere. But instead of going on about how const is so great, I’m going to let Hitler tell us how he really feels about it.
No Flash? Try the QuickTime video version.
Let me get one thing out of the way to stop all the trigger-happy, const-bashing, would-be-commenters: const doesn’t make any guarantees that values don’t change.
You can change a const variable by casting the constness away, or referencing it through a pointer, but you really had to go out of your way to do that. If it helped with that, const would solve (or improve) the memory aliasing problem like Hitler pointed out. It doesn’t, so const is pretty weak as far as promises go. It just says “I, the programmer, promise not to change this value on purpose (unless I’m truly desperate)”. Still, even a promise like that goes a long way helping with readability and maintenance.
With that out of the way, what exactly do I mean by using const everywhere?
Const non-value function parameters
Any reference or pointer function parameters that are pointing to data that will not be modified by the function should be declared as const. If you’re going to use const just for one thing, this is the one to use. It’s invaluable glancing at a function signature and seeing which parameters are inputs and which ones are outputs.
void Detach(PhysicsObject& physObj, int attachmentIndex, const HandleManager& mgr);
Marking those parameters as const also serves as a warning sign in case a programmer in the future tries to modify one of them. Imagine the disaster if the calling code assumes data never changes, but the function suddenly starts modifying that data! const won’t prevent that from happening, but will remind the programmer that he’s changing the “contract” and needs to revisit all calling code and check assumptions.
Const local variables
This is a very important use of const and one of the ones hardly anyone follows. If I declare a local (stack) variable and its value never changes after initialization, I always declare it const. That way, whenever I see that variable used later in the code, I know that its value hasn’t changed.
const Vec2 newPos = AttachmentUtils::ApplySnap(physObj, unsnappedPos); const Vec2 deltaPos = newPos - physObj.center; physObj.center = newPos;
This is one of the reasons why I did a 180 on the ternary C operator (?). I used to hate it and find it cryptic and unreadable, but now I find it compact and elegant and it fulfills my const fetish very well.
Imagine you have a function that is going to work in one of two objects and you need to compute the index to the object to work on. You could do it this way:
int index; if (some condition) index = 0; else index = 2; DoSomethingWithIndex();
Not only does that take several lines not to do much, but index isn’t const (argh!). So every time I see index anywhere later on in that function, I’m going to have to spend the extra mental power to make sure nothing has changed (and, with my current coding style, I would assume it has changed).
Instead, we can simply do this:
const int index = (some condition) ? 0 : 2; DoSomethingWithIndex();
Ahhhh… So much better!
Const member variables
This one doesn’t really apply to me anymore because I don’t use classes and member variables. But if you do, I strongly encourage you do mark every possible member function as const whenever you can.
The only downside is that sometimes you’ll have some internal bit of data that is really not changing the “logical” state of an object, but it’s still modifying a variable (usually some caching or logging data). In that case, you’ll have to resort to the mutable keyword.
Const value function parameters
 Apparently I’m not a total Const Nazi because this is one possible use of const that I choose to skip (even though I tried it for a while because of Charles).
Apparently I’m not a total Const Nazi because this is one possible use of const that I choose to skip (even though I tried it for a while because of Charles).
Marking a value function parameter as const doesn’t make any difference from the calling code point of view, but it serves the same purpose as marking local stack variables as const in the implementation of the function. You’re just saying “I’m not going to modify that parameter in this function” so it makes the code easier to understand.
I’m actually all for this, but the only reason I’m not doing it is because C/C++ makes it a pain. Marking parameters as const in the function declaration adds extra verbosity and doesn’t help the person browsing the functions at all. You could actually put the const only in the function definition and it will work, but at that point the declaration and the definition are different, so you can’t copy and paste them or use other automated tools or scripts.
The concept of const is one of the things I miss the most when programming other languages like C#. I don’t understand why they didn’t add it to the language. On something like Python or Perl I can understand because they’re supposed to be so free form, but C#? (Edit: How about that? Apparently C# has const. It was either added in the last few years or I completely missed it before). It also really bugs me that Objective C or the Apple API doesn’t make any use of const.
Frankly, if it were up to me, I would change the C/C++ language to make every variable const by default and adding the nonconst or changeable (or take over mutable) keyword for the ones you want to modify. It would make life much more pleasant.
But then again, that’s why the call me the Const Nazi.
This post is part of iDevBlogADay, a group of indie iPhone development blogs featuring two posts per day. You can keep up with iDevBlogADay through the web site, RSS feed, or Twitter.
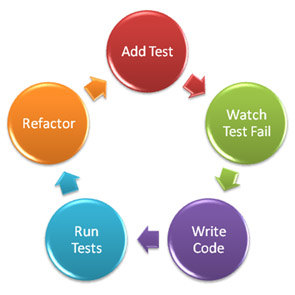 By giving up on TDD for high-level code, you’ll be missing out on the main benefit of TDD: designing better code. I’ve said this many times, but it bears repeating: TDD is not a testing technique. It’s a design technique. You get lots of benefits from applying TDD
By giving up on TDD for high-level code, you’ll be missing out on the main benefit of TDD: designing better code. I’ve said this many times, but it bears repeating: TDD is not a testing technique. It’s a design technique. You get lots of benefits from applying TDD  Every developer who’s been working on a team for a while is able to tell the author of a piece of code just by looking at it. Sometimes it’s even fun to do a forensic investigation and figure out not just the original author, but who else modified the source code afterwards.
Every developer who’s been working on a team for a while is able to tell the author of a piece of code just by looking at it. Sometimes it’s even fun to do a forensic investigation and figure out not just the original author, but who else modified the source code afterwards.