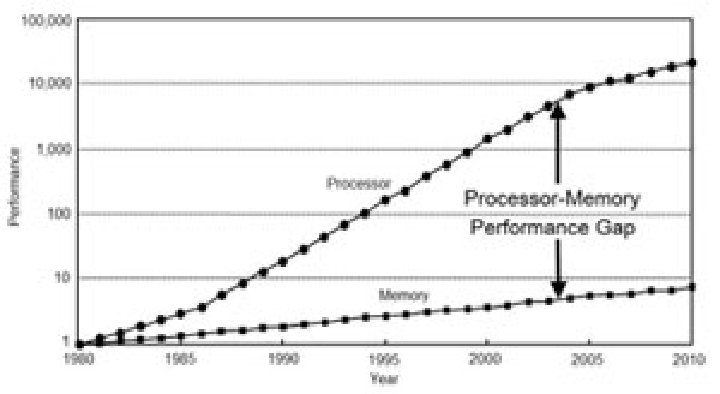
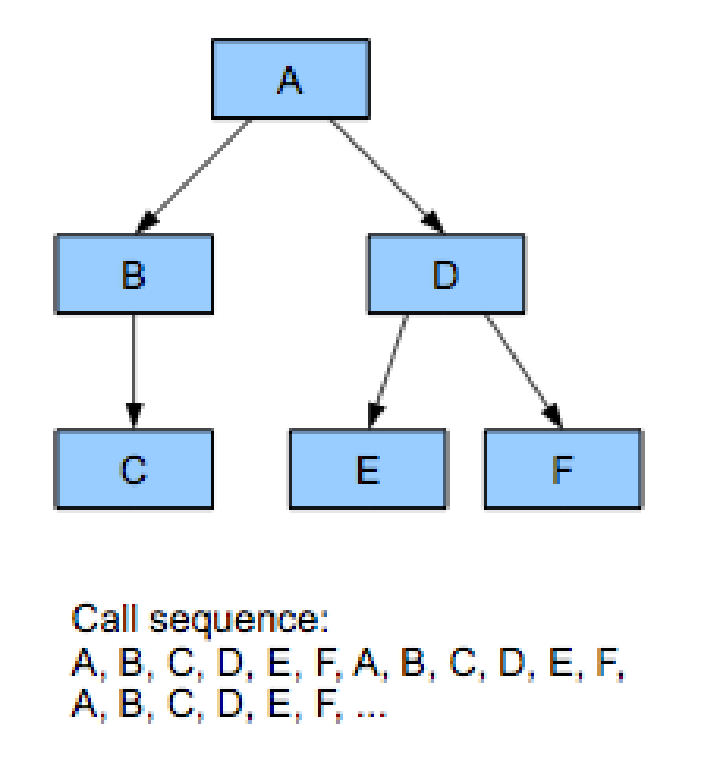
Data-Oriented Design Now And In The Future
There has been a lot of recent discussion (and criticism) on Data Oriented Design recently. I want to address some of the issues that have been raised, but before that, I’ll start with this reprint from my most recent Game Developer Magazine. If you have any questions you’d like addressed, add write a comment and I’ll try to answer everything I can. Last year I wrote about the basics of Data-Oriented Design (see the September 2009 issue of Game Developer). In the time since that article, Data-Oriented Design has gained a lot of traction in game development and many of teams are thinking in terms of data for some of the more performance-critical systems. ...