Today I have the pleasure to introduce the first-ever guest post in Games From Within, Joey Chang. Like me, Joey worked for many years in the game industry, and finally took the plunge last October to become an independent game developer. Unearthed is his first iPhone project and it’s a very unique free to play, augmented reality (AR) game with an X-Files-like theme.
Joey was kind enough to share the story behind Unearthed, some of the decisions leading up to the final game, and the initial reception and sales numbers. Thanks Joey!
Inspiration
Nine months ago, without warning, a gnome crept into my head. It was an idea inspired from a friend’s chance mention of an activity called geocaching, where participants use a GPS to hide and seek containers across the world. Within hours, I had envisioned a global cross between geocaching, the Amazing Race, and online travel agency representatives. The idea didn’t look much like the resultant product nine months later, but it formed the most critical ingredient to any venture: the obsession to see it completed.
I spent my evenings for a few short weeks hammering out a design, scoping and cutting features, and beginning a prototype, but it didn’t take long for me to admit to the unavoidable truth that such a project would take months working full time or probably 3 to 4 times as many months working nights and weekends. I had to sit and carefully consider the pros and cons of leaving my job to pursue something I desperately wanted to create.
Half-Hearted Dissent
 For two weeks, I debated with my wife and close friends with startup experience. I drafted a list of pros and cons to quitting my job to pursue an iphone project and stared at it for hours. Those of you who have made the leap or considered it may recognize some of the points or have more of your own to add:
For two weeks, I debated with my wife and close friends with startup experience. I drafted a list of pros and cons to quitting my job to pursue an iphone project and stared at it for hours. Those of you who have made the leap or considered it may recognize some of the points or have more of your own to add:
Advantages of quitting to work full time on an iphone idea
- Focus effort, complete project 3-4 times faster
- Gain valuable unique experience of running solo
- Avoid coding burnout, alienating loved ones, loss of sanity
- Resume padding
Advantages of keeping day job while working on iphone idea
- Steady income in a scary economy
- Not having to job search in a scary economy
- Peace of mind (in a scary economy)
You can see where a large portion of the dissenting argument forms its basis. After two weeks of listening to unanimous encouragement (bordering on persistent nagging) to quit my job, two weeks of trying my best to convince myself why I should not quit my job, I did what my gut knew from day one was going to be best for me. I marched to my boss’s room and quit my job. Ok, I had maybe two false starts where I turned around and went back to my seat.
The Project Unearthed
Over the next 8 months, scoping and an inclination to appeal to a casual segment evolved the project into a global paranormal investigation titled Unearthed. I tried my best to figure how to maximize the success of the product, and compiled a list of all the ways I could imagine increasing the product’s exposure:
- Banner ads
- Spamming blogs and websites to review my product
- Spamming friends on facebook
- Writing a blog
- Viral app features
I had trouble justifying the cost to pay for banner ads, and I had too much urgency to implement the product to devote time to a blog, so I focused on occasionally talking about the app on facebook, compiling a list of potential blog candidates for the day the app released, and devising viral features.
 Apart from typical facebook posting and email-a-friend features, I decided to employ a “refer-an-agent” feature which would enable users to invite others to join their network, essentially a grouping of users that correlated with how effectively their app could process scanned creature data. The larger the network, the more credit users would receive for uploading data, and the better they would perform in leaderboards and achievements. The approach was an “everybody wins” style where anytime any user in the network gained a referral, every single person in the network would benefit from the growth of the network. The hope was that this feature would gain a viral quality.
Apart from typical facebook posting and email-a-friend features, I decided to employ a “refer-an-agent” feature which would enable users to invite others to join their network, essentially a grouping of users that correlated with how effectively their app could process scanned creature data. The larger the network, the more credit users would receive for uploading data, and the better they would perform in leaderboards and achievements. The approach was an “everybody wins” style where anytime any user in the network gained a referral, every single person in the network would benefit from the growth of the network. The hope was that this feature would gain a viral quality.
Friends placed immense pressure to release the product as soon as humanly possible under the theory that doing so would reveal the 70% of my design that was wrong, so I divided Unearthed into three releases. The app itself has three game modes, each incrementally accessible as a given region “levels up” from users’ data uploads. I would have time to release the latter modes while the first mode of the game, the most casual mode where users look around where they stand and scan for anomalies, was being played.
In App Purchases and Ads
 Considering the App Store was flooded with free apps and that I had no name in the industry to immediately convince users to immediately pay for my app, I concluded that the most likely approach for success was to release a free app with In App Purchases. This appeared to be the best way to get as many users to at least try the app and decide how much they wanted to spend to access more functionality. Initially, I offered the following items:
Considering the App Store was flooded with free apps and that I had no name in the industry to immediately convince users to immediately pay for my app, I concluded that the most likely approach for success was to release a free app with In App Purchases. This appeared to be the best way to get as many users to at least try the app and decide how much they wanted to spend to access more functionality. Initially, I offered the following items:
- All content, present and future ($5.99)
- Scanner upgrades level 2-3 ($1.99)
- Scanner upgrades level 4-5 ($1.99)
- Bounty Mode (coming soon) ($1.99)
- Blitz Mode (coming soon) ($1.99)
However, I hit a snag with Apple’s terms which did not permit me to even mention any features that were not yet implemented. The first item was intended to be a bulk pricing investment in the forthcoming completion of the app, and the ‘coming soon’ items were just client-side displays to tease of the future modes (not actually registered products in the IAP servers). Because I had to remove them, I revised my IAP content to the following:
- Scanner upgrades level 2 ($.99)
- Scanner upgrades level 3 ($.99)
- Scanner upgrades level 4 ($.99)
- Scanner upgrades level 5 ($.99)
- Scanner upgrades 2-5 ($2.99)
The app essentially gives users access to all features of the game, but with a lowly basic scanner that doesn’t boast the speed, range, and creature clearance levels of a fully boosted scanner.
I added Greystripe’s ad system as a means to offset the cost I might incur from using Google App Engine as my server solution. Considering the large amount of rank tracking required by my app, I estimated the revenue from ads to break even with the cost of using App Engine.
Release and Reception
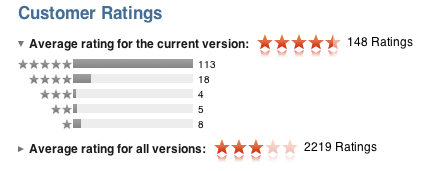
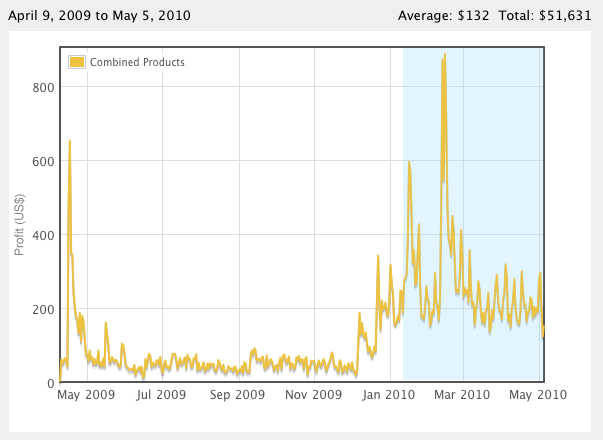
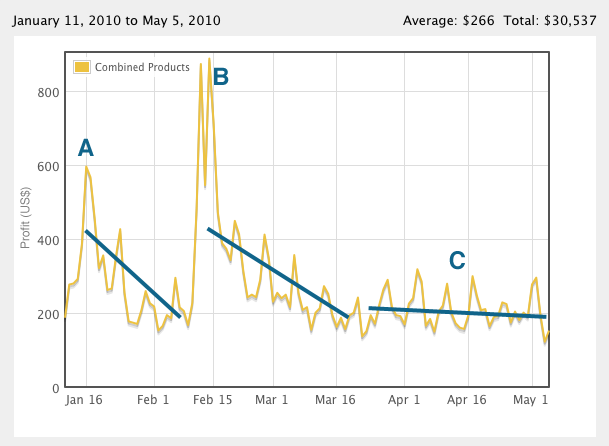
The app was approved in the early afternoon of June 21st, a Monday. Excited, I quickly moved up the release date and it hit the stores later that afternoon. One week later, the sales are dismal, with about 400 total downloads and only a handful of purchases.
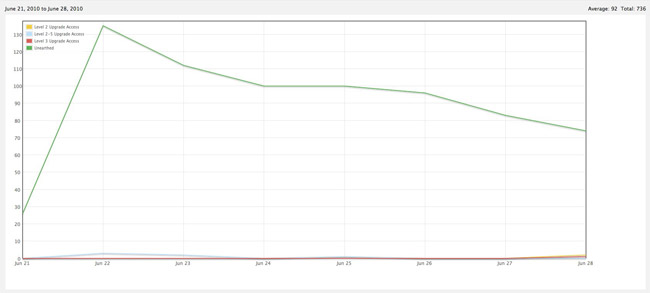
I considered possible contributors to this could be the following (in order of impact):
- Requiring 3GS
- Releasing 4 days before the iPhone 4 (dropping off New Releases)
- Requiring OS 3.1.3 (instead of 3.1)
- Releasing the app in the late afternoon (dropping off New Releases faster)
Without knowing the specifics on the sales of the 3GS versus the 3G and the iPod Touch, the fraction of 3GS users able to even see my app in the store might be a small fraction. Unnecessarily releasing under an OS that prevented users from installing unless they went back to iTunes to update their OS was likely a dealbreaker for browsing users (quickly remedied but days later). And considering how many of the 1.5 million users would be browsing the App Store for free apps Thursday, releasing a few days too early may have been the biggest avoidable mistake yet.
Moving Forward
As uninspiring as it was getting only a few hundred downloads and enough revenue for lunch, I had heard that word of mouth was a powerful vehicle, possibly the best vehicle, for an unknown developer, so my plan is to continue giving it more time and implement the GPS-enabled Bounty Mode which will take considerably less time, possibly a short 1-2 months. One week is certainly not a large enough measure of success, and already I’ve received a few responses from blogs willing to write reviews, so I’m hopeful of seeing the userbase grow and eagerly anticipating the next big server issue. In the coming weeks, there will definitely be no “sitting back while the cash rolls in”, as I recently had the blessing/curse of another inspiring must-create iPad app revelation and am sweating bullets designing and scoping while scheduling in work on Unearthed, all the while keeping a grave eye on the lifeline of my business.
Looking back at the struggling decision I made to quit my job, I’m reminded of some advice that was given to me beforehand. “Quitting your job will be the hardest decision, but it will make you feel great.” And like an enormous burden lifted from me, it did. And to this day, with earned lunch money in hand, it continues to.
 Every developer who’s been working on a team for a while is able to tell the author of a piece of code just by looking at it. Sometimes it’s even fun to do a forensic investigation and figure out not just the original author, but who else modified the source code afterwards.
Every developer who’s been working on a team for a while is able to tell the author of a piece of code just by looking at it. Sometimes it’s even fun to do a forensic investigation and figure out not just the original author, but who else modified the source code afterwards.