I’ve been making computer games in some form or another for just over 25 years now. At the very beginning, as a hobby (passion) and completely by myself (although not for lack of trying to get some of my friends involved). In the late 90s, when I finally left academia and started making games professionally, teams were still relatively small, with a total of around 10-15 people per team. As we all know, budgets and scopes kept growing, and so did team sizes. At its peak, the largest team I worked at had around 200 people. That’s when I decided to go indie and started Power of Two Games, which was obviously just two of us. Finally, now as Snappy Touch, I’ve gone full circle: It’s just me again.
 Development tools and hardware have changed quite a bit from the times I was writing in straight Z80 assembly and saving the programs to a tape. But I’ve also changed and learned a lot during all those years developing games, and even though I’m writing games by myself again, I’m doing things very differently from how I did them back at the start.
Development tools and hardware have changed quite a bit from the times I was writing in straight Z80 assembly and saving the programs to a tape. But I’ve also changed and learned a lot during all those years developing games, and even though I’m writing games by myself again, I’m doing things very differently from how I did them back at the start.
One thing that I’ve always done is to question everything. Why should I do things a certain way? Why is that the “accepted” way of doing something? And not surprisingly, at each step of the way, I’ve changed my development style to match my situation (often in ways that went against the “common wisdom”).
When it comes to solo development, I rely heavily on the concept of goals and iterations at multiple levels:
- Immediate (< 1 minute): Prioritizing the ideas going through my mind. Writing tests. Writing code.
- Short Range (< few hours): Tasks that move the project forward in some way.
- Mid Range (< 2 weeks): “Stories” that define a self-contained, significant part of the project.
- Long Range (full project, several months): Ship date, beta testing, etc.
It turns out, I use a different set of tools to help me manage the items at each level of the development cycle.
Immediate
These are the actions I take and complete in less than a minute or two. Most of them are writing tests (with UnitTest++, of course), writing code to make those tests pass, refactor code, and check it into Subversion. I have my Subversion repository hosted on Dreamhost and I access it through SSH so it’s secure, accessible from anywhere with an internet connection (or 3G signal and HandyLight), offsite, and easy to backup. And because Subversion works great offline (unlike Perforce), it’s not a problem to work without connection to the repository for a while.
I also need to manage my minute-to-minute thoughts, write down ideas and reprioritize them when the time comes. When I’m “in the zone”, I get way more ideas than I can execute with my fingers: This function needs to be moved to a different file, I really should be compacting that data over there, who was stupid enough to name this file this way?, that variable shouldn’t be cached, etc. If I don’t write things down, I will either forget them, or I’ll stress for hours until I finally get around to doing them. I could also do things as I think about them, but then I would be chasing a rabbit down a neverending hole and wouldn’t get any work done (I’m sure anybody who’s gotten lost browsing web pages can identify with that).
I used to do this the old-fashioned way, simply with paper and pencil (like Bob described in his blog post). However, I found that physical paper and pencil was just too limiting: I can type a lot faster than I can write, switching to writing requires moving away from the keyboard, and, most importantly, I need to bring the notes with me everywhere and it’s very difficult to rearrange, sort, or coalesce them in any way.
So instead, my tool of choice these days is JustNotes. It’s perfect for jotting down thoughts in a matter of seconds without even interrupting my train of thought. I have JustNotes bound to a global key, so in the middle of typing a line of code, I can press that key, enter whatever I’m thinking about, press the key again, and finish the line of code. All in 4-5 seconds. Don’t laugh: The fact that I can do that in just a few seconds without moving my hands away from the keyboard means I can use it any time without much penalty. It’s amazing how many things I jot down that I wouldn’t do otherwise.
Short Range
To manage tasks up to a few hours in length, I use Trac. Trac is a fantastic issue-tracking tool: It’s free, it’s fast, it’s simple, and it’s configurable. In the past I’ve used anything from spreadsheets, to Bugzilla, to publisher-owned bug databases, and nothing comes close to Trac for my needs. It also scales very well to teams of more than one person (although it might not be good enough for hundreds of people).
Just like Subversion, I have Trac hosted externally, through my web hosting company. Sometimes it’s frustrating if I need to access it and the server is down, but again, the convenience of having it off site makes it well-worth it.
Any task that requires more than 10-15 minutes goes in Trac, and then I can easily prioritize tasks depending on their importance. Usually, if an item has been on my instant queue in JustNotes for about a day and I haven’t gotten around to it, it either gets deleted or it gets moved into a full item in Trac. The only way progress happens is by ticking off Trac tasks. In the end, my projects live and die by Trac.
Medium Range
User stories (to borrow terminology from Scrum/XP) are visible, relatively self-contained features of the final project. They’re made up of several tasks, and usually take a few days to a few weeks to implement. A group of user stories make up a full iteration (sprint) of the game, which is usually between one and two weeks long. Sometimes user stories are complex enough (add a replay feature visible on the web site) that the full iteration is just the one user story.
I keep track of these stories in Trac as well. Trac is both an issue-tracking system and a wiki, so the wiki part is perfect to keep these user stories. In addition to that, I label tasks as belonging o a particular iteration. That allows me to separate what needs to be done for this iteration, from other tasks that I added for the future. At the start of each iteration, I decide on the user stories and either generate new tasks or label existing tasks as due for this iteration.
The wiki in Trac is extremely valuable for all sorts of other things: game design ideas, general brainstorming, gathering reference material, etc.
Trac ends up being the perfect mid-range vision of my project.
Long Range
User stories and tasks in Trac aren’t enough to cover a project that is potentially 3-4 months long. I need something that helps me with the longer view, otherwise I find that things creep up on me without realizing it because I’m so focused on the short and mid-range items.
The best tool I’ve found so far is very low-tech: A printable month-per-page calendar covering the full length of the project. Right now I’m shooting for a November release of my current project, so I printed August, September, October, and November and pinned them to the corkboard on my office. It’s amazing the sense of urgency that seeing your ship date gives you. You realize that you only have a handful of weeks before shipping and makes it much easier to prioritize tasks (and chop off features or save them for an update).
I realize this long-term, calendar view isn’t very useful if you don’t have a set release date and you want to continue chipping at your game until it’s ready. But even if your release date is flexible, having this long-term view can help you keep budgets in perspective and manage them accordingly.
Finally, for an extra bit of motivation (or maybe this falls in the category of excessive pressure), I just started using a countdown widget for the Mac OS Dashboard. Just in case the calendar view wasn’t enough, here’s a countdown (down to the second) of the time left until release.
Speaking of which, I think it’s time I get back to work. Only 102 days left!
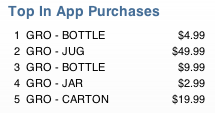
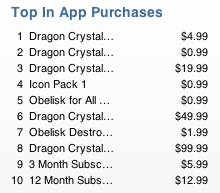
 In-game point bundles are nothing new. Even before the time of in-app purchases,
In-game point bundles are nothing new. Even before the time of in-app purchases, 

 The basics of mocking objects are as simple as what we’ve seen. Armed with that knowledge, you can go ahead and test all the object interactions in your code. However, I bet that you’re going to get tired quickly from all that typing every time you create a new mock. The bigger and more complex the object is, the more tedious the operation becomes. That’s where a mocking framework comes in.
The basics of mocking objects are as simple as what we’ve seen. Armed with that knowledge, you can go ahead and test all the object interactions in your code. However, I bet that you’re going to get tired quickly from all that typing every time you create a new mock. The bigger and more complex the object is, the more tedious the operation becomes. That’s where a mocking framework comes in.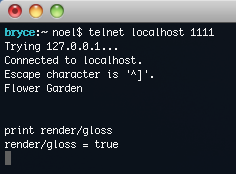 Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.
Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.