
By now every iOS developer knows that making a great game and putting it on the App Store is only part of the work. In order to get significant sales, it needs to be noticed. You need to spend a significant amount of time in marketing and PR, making sure that blogs cover it, magazines review it, or at least jump-starting it with a group of devoted and vocal forum fans.
Most often, the advice stops there. So you get your initial sales spike and then sales go way down. What do you do then? Usually, developers release new features and updates. That’s great, but how do you get people to notice it. You need to establish some form of communication with your players.
Update Messages
The simplest form of communication is through the “What’s new” section in the update. You can use that section not just to list what features you added and what bugs you fixed, but also to let your players know about other things: plans for the future, other games to try, or even the URL for your Facebook group.
Credit goes to Igor for bringing up this idea and pointing out the URLs are even clickable in this field (but they aren’t in the app description).
Of course, if you’re like me and you update your apps only once in a while, this technique isn’t as effective. Right now my iPhone tells me I have 67 new updates available. I’m clearly not going to be reading through the release notes of each one.
In-Game News
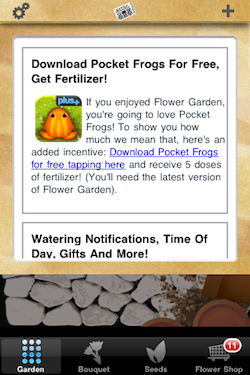 A more direct way of reaching out to your players is to have some sort of in-game news system. At any point you can update a file in your web server with any news, and it is displayed in the game. It can be implemented in many different ways depending on “on your face” you want to be about it: a pop up that comes up when the user runs the game, a ticker that runs constantly across the bottom of the screen, or, what I did for Flower Garden, a news icon with a badge indicating how many unread items there are, that brings up the news page when you tap it.
A more direct way of reaching out to your players is to have some sort of in-game news system. At any point you can update a file in your web server with any news, and it is displayed in the game. It can be implemented in many different ways depending on “on your face” you want to be about it: a pop up that comes up when the user runs the game, a ticker that runs constantly across the bottom of the screen, or, what I did for Flower Garden, a news icon with a badge indicating how many unread items there are, that brings up the news page when you tap it.
Make sure players are able to click on URLs in your news messages so you can direct them to different web pages easily. More on that on a bit.
Emails
Update messages are only good for players who update their apps (ahem, ahem), and in-game news for active players who’re currently launching your apps. For maximum effect, you can send an email newsletter and that way you can also reach users who played the game at some point in the past, but aren’t currently playing it now. They’re the ones probably most interested in new updates and features, and chances are you can rekindle their interest in the game.
To do this, you should encourage users to register for your mailing list, or collect their emails with their consent in some other way. This was a technique I started using back in December of last year with great success.
I’m currently using Your Mailing List Provider as a means to delivering thousands and thousands of emails [1]. By the way, don’t miss a chance to join the Flower Garden mailing list 🙂
Similar to the mailing list approach, Facebook groups can be a very effective form of communication. An additional benefit is that friends of your players might see them participating in the page and might make them try out your game.
Case Study: Pocket Frogs Cross-Promotion
All that is fine in theory. How does it work in practice? I have been using all four forms of communication for a while, and I’m definitely seeing good bumps of sales and downloads with each update and each major communication.
Last week, Ian and Dave from Nimblebit and I, decided to set up a cross promotion between Pocket Frogs and Flower Garden.
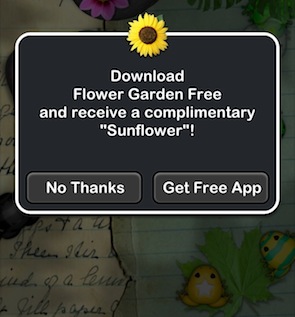
I updated the in-game news and send out an email newsletter coinciding with the latest Flower Garden update telling the players that if they downloaded Pocket Frogs from within Flower Garden, they would be awarded 5 doses of fertilizer. Nimblebit awarded players a flower if they downloaded Flower Garden Free from within Pocket Frogs.
When you have over a million downloads in a week like Pocket Frog did, that kind of player communication is the equivalent of a nuclear cannon. The effects of the cross-promotion were obvious the instant the news went live:
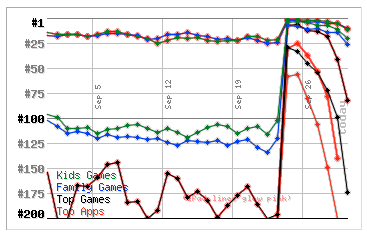
As you can see, Flower Garden Free made it all the way to the number 56 in the iPhone Top Apps chart in the US! The effect even spread to the paid version of Flower Garden:
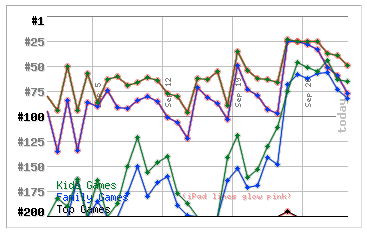
Pocket Frogs at the time was hovering at around #9 on the charts, so it was difficult to have much of an impact on that position without major numbers, but we suspect it might have hovered there a little longer because of the extra downloads from Flower Garden.
Here is what the downloads for Flower Garden Free looked like for the last month. The Pocket Frogs cross-promotion is quite noticeable:
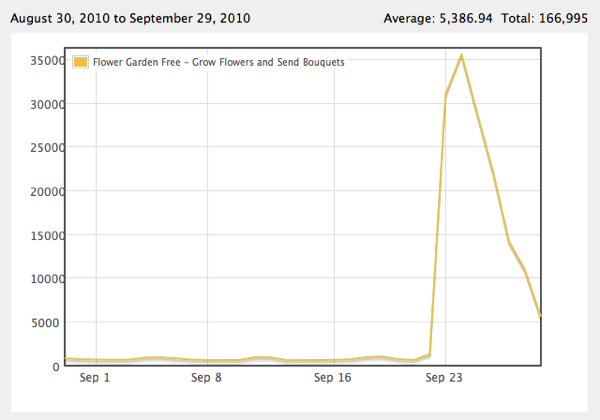
All those downloads also translated into in-app sales through the Flower Shop. Here are the revenues for that time period:
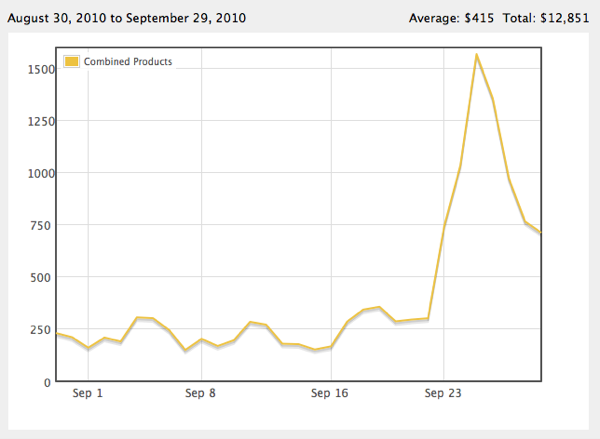
One consequence I wasn’t expecting, but in retrospect I’m not that surprised about, is that the ratings for Flower Garden Free dropped by a whole star (from 4 to 3), with a large percentage of 1-star reviews. That’s because a lot of people who wouldn’t have downloaded Flower Garden otherwise did it anyway, didn’t like it, and deleted it right away.
To wrap things up on a better note, there was yet another side effect of the cross promotion. The Pocket Frogs link was using my LinkShare referral code. Sending all those users to the App Store to download a free game link resulted in about $200 in referral profit for the week.
Conclusion
Communicating with your players is more than just profitable: It’s crucial to the sustained success of your games. Make sure you try to engage with them in every way you can, keep them up to date with developments in your game, and don’t hesitate to run the occasional cross-promotion, especially with other games that are a good match for your target audience.
[1] If you decide to use them and wouldn’t mind using my referral code (WQHVUF), I can get a small percentage back.
This post is part of iDevBlogADay, a group of indie iPhone development blogs featuring two posts per day. You can keep up with iDevBlogADay through the web site, RSS feed, or Twitter.
 So I decided to start cheap and work my way up from the bottom. First I had to decide if I even liked this whole working-while-standing thing. I wasn’t even sure I would be able to type! I thought about raising my desk with cinder blocks, but I would have to raise a lot and would make it very unstable. So instead, I created four stacks of books on top of my desk and put a board on top. Then I was able to put the keyboard, computer, and monitor on the board and give that a try.
So I decided to start cheap and work my way up from the bottom. First I had to decide if I even liked this whole working-while-standing thing. I wasn’t even sure I would be able to type! I thought about raising my desk with cinder blocks, but I would have to raise a lot and would make it very unstable. So instead, I created four stacks of books on top of my desk and put a board on top. Then I was able to put the keyboard, computer, and monitor on the board and give that a try. At this point I decided that the stack of books was too annoying, but I wasn’t quite ready for an expensive desk. So I picked up a
At this point I decided that the stack of books was too annoying, but I wasn’t quite ready for an expensive desk. So I picked up a 

 I’m defining lag as the time elapsed between the moment the player performs an input action (press a button, touch the screen, move his finger), until the game provides some feedback for that input (movement, flash behind a button, sound effect).
I’m defining lag as the time elapsed between the moment the player performs an input action (press a button, touch the screen, move his finger), until the game provides some feedback for that input (movement, flash behind a button, sound effect).
 Even though I was pretty much completely new to the Google App Engine (I had looked into it briefly before the launch of Flower Garden but dismissed it because they couldn’t support the amount of email traffic I needed), it took me two days to port over everything. Actually flipping the switch from the old system to the new one took a while longer, but that required more courage than work. More on that later.
Even though I was pretty much completely new to the Google App Engine (I had looked into it briefly before the launch of Flower Garden but dismissed it because they couldn’t support the amount of email traffic I needed), it took me two days to port over everything. Actually flipping the switch from the old system to the new one took a while longer, but that required more courage than work. More on that later. So
So