
Some people asked what I meant by a “toolkit architecture” in the previous post about my middleware fears. It turns out I wrote about that in a previous Inner Product column that for some reason I never reposted here. I think at the time I wrote this (late 2008), I already wasn’t very concerned about writing reusable code, and I was focusing it mostly with respect to using other people’s code and how I wanted it to be architected.
Game tech
There are 21 posts filed in Game tech (this is page 2 of 5).
My Fear of Middleware
Once upon a time, the idea of using some kind of middleware or major external library in my projects was out of the question. Writing all my code was the one and true way! I had a bad case of NIH syndrome.
Over the years I’ve mellowed out quite a bit. Now I recognize my obsession with writing endless tools and technology was more of an escape from doing the really hard part of game development. In comparison to making all the decisions involved in the design and implementation of the game itself, writing the perfect resource streaming system sounds like a really good time. It’s amazing how early it started too: I still remember spending weeks writing a Basic-to-assembly translator in 1986, before I had even heard the word “compiler”.
Now I just want to make games.
The Curious Case of Casey and The Clearly Deterministic Contraptions
As we gear up for Casey’s Contraptions launch on May 19th, this is the first post in a series dealing with different aspects of the game. I’m planning on covering technical aspects like today, but also design and other parts of development.

For those of you who have been living under a rock and haven’t seen the Casey’s Contraptions video, go watch it now. I’ll wait. Or even better, here it is. You don’t even have to leave this page:
Start Pre-allocating And Stop Worrying
One of the more frequent questions I receive is what kind of memory allocation strategy I use in my games. The quick answer is none (at least frame to frame, I do some allocation at the beginning of each level on a stack-based allocator). This reprint of one of my Inner Product column covers quite well how I feel about memory allocation.
We’ve all had things nagging us in the back of our minds. They’re nothing we have to worry about this very instant, just something we need to do sometime in the future. Maybe that’s changing those worn tires in the car, or making an appointment with the dentist about that tooth that has been bugging you on and off.
Dynamic memory allocation is something that falls in that category for most programmers. We all know we can’t just go on allocating memory willy-nilly whenever we need it, yet we put off dealing with it until the end of the project. By that time, deadlines are piling on the pressure and it’s usually too late to make significant changes. With a little bit of forethought and pre-planning, we can avoid those problems and be confident our game is not going to run out of memory in the most inopportune moment.
On-Demand Dynamic Memory Allocation
 The easiest way to get started with memory management is to allocate memory dynamically whenever you need it. This is the approach many software engineering books consider as ideal and it’s often encouraged in Computer Science classes.
The easiest way to get started with memory management is to allocate memory dynamically whenever you need it. This is the approach many software engineering books consider as ideal and it’s often encouraged in Computer Science classes.
It’s certainly an easy approach to use. Need a new animation instance when the player is landing on a ledge? Allocate it. Need a new sound when we reach the goal? Just allocate another one!
On-demand dynamic memory allocation can help to keep memory usage to a minimum, because, you only allocate the memory that you need and no more. In practice it’s not quite as neat and tidy because there can be a surprisingly large amount of overhead per allocation, which adds up if programmers become really allocation-happy.
It’s also a good way to shoot yourself in the foot.
Games don’t live inside a Computer Science textbook, so we have to deal with real world limitations, which make this approach cumbersome, clunky, and potentially disastrous. What can go wrong with on-demand dynamic memory allocation? Almost everything!
Limited Memory
Games, or any software for that matter, run on machines with limited amounts of memory. As long as you know what that limit is, and you keep extremely careful track of your memory usage, you can remain under the limit. However, since the game is allocating memory any time it needs it, there will most likely come a time when the game tries to allocate a new block but there is no memory left. What can you do then? Nothing easy I’m afraid. You can try to free an older memory block and allocate the new one there, or you can try to make your game tolerant to running out of memory. Both those solutions are very complex and difficult to implement correctly.
Even setting memory budgets and sticking to them can be very difficult. How can a designer know that a given particle system isn’t going to run out of memory? Are these AI units going to create too many pathfinding objects and crash the game? Hard to say until we run the game in all possible combinations. And even then, how do you know it isn’t going to crash five minutes later? Or ten? It’s almost impossible to know for certain.
If you insist in using this approach, at the very least, you should tag all memory allocations, so you have an idea of how memory is being used. You can either tag each allocation based on what system initiated it (physics, textures, animation, sound, AI, etc) or even on the filename where it originated, which has the advantage that it can be automated and should still give you a good picture of the overall memory usage.
Memory Fragmentation
Even if you take lots of pain not to go over your the available memory, you might still run into trouble because of memory fragmentation. You might have enough memory for a new allocation, but in the form of many small memory blocks instead of a large contiguous one. Unless you provide your own memory allocation mechanism, fragmentation is something that is very hard to track on your own, so you can’t even be ready for it until the allocation fails.
Virtual Memory
Virtual memory could solve all those problems. In theory, if you run out of real memory, the operating system swaps out some older, unused pages to disk and makes room for the new memory you requested. In practice, it’s just a bad caching scheme because it can be triggered at the worst possible moment, and it doesn’t know about what data it’s swapping out or how your game uses it.
Games, unlike most other software, have a “soft realtime” requirement: The game needs to keep updating at an acceptable interactive rate, which is somewhere around 15 or more frames per second. That means that gamers are going to make a trip to the store to return your game if it pauses for a couple of seconds every few minutes to “make some room” for new memory. So relying on virtual memory isn’t a particularly attractive solution.
Additionally, lots of games run in platforms with fixed amounts of RAM and no virtual memory. So when memory runs out, things won’t get slow and chuggy, they’ll crash hard. When the memory is gone, it’s really gone.
Performance Problems
There are some performance issues that are relatively easy to track down and fix. Usually ones that occur every frame and are happening in a single spot: some expensive operation, a O(n3) algorithm, etc. Then there are performance problems introduced by dynamic memory allocations, which can be really hard to track down.
Standard malloc returns memory pretty quickly, and usually doesn’t ever register on the the profiler. Every so often though, whenever the game has been running for a while and memory is pretty fragmented, it can spike up and cause a significant delay for just a frame. Trying to track down those spikes has caused more than one programmer to age prematurely. You can avoid some of those problems by using your own memory manager, but don’t attempt to write a generic one yourself from scratch. Instead start with some of the ones listed in the references.
Malloc spikes are not the only source of performance problems. Allocating many small blocks of memory can lead to bad cache coherence when the game code access them sequentially. This problem usually manifests itself as a general slowdown that can’t be narrowed down in the profiler. With today’s hardware of slow memory systems and deep caches, good memory access patterns are more important than ever.
Keeping Track Of Memory
Another source of problems with dynamic memory allocation are bugs in the logic that keeps track of the allocated memory blocks. If we forget to free some of them, our program will have memory leaks and has the potential to run out of memory.
The flip side of memory leaks are invalid memory access. If we free a memory block and later we access it as if it were allocated, we’ll either get a memory access exception, or we’ll manage to corrupt our own game.
Some techniques, such as reference counting and garbage collection can help keep track of memory allocations, but introduce their own complexities and overhead.
Introducing Pre-allocation
On the opposite corner of the boxing ring is the purely pre-allocated game. It excels at everything that the dynamically-allocated game is weak at, but it has a few weaknesses of its own. All in all, it’s probably a much safer approach for most games though.
The idea behind a pre-allocation memory strategy is to allocate everything once and never have to do any dynamic allocations in the middle of the game. Usually you grab as big a block of memory as you can, and then you carve it out to suit your game’s needs.
Some advantages are very clear: no performance penalties, knowing exactly how your memory is used, never running out of memory, and no memory fragmentation to worry about. There are some other more subtle advantages, such as being able to put data in contiguous areas of memory to get best cache coherency, or having blazingly-fast load times by loading a baked image of a level directly into memory.
The main drawback of pre-allocation is that is more complex to implement than the dynamic allocation approach and it takes some planning ahead.
Know Your Data
For preallocation to work, you need to know ahead of time how much of every type of data you will need in the game. That can be a daunting proposition, especially to those used to a more dynamic approach. However, with a good data baking system (see last month’s Inner Product column), you can get a global view of each level and figure out how big things need to be.
There is one important design philosophy that needs to be adopted for preallocation to work: Everything in the game has to be bounded. That shouldn’t feel too restrictive; after all, the memory in your target platform is bounded, as well as every single resource. That means that everything that can create new objects, including high-level game constructs, should operate on a fixed number of them. This might seem like an implementation detail, but it often bubbles up to what’s exposed to game designers. A common example is an enemy spawner. Instead of designing a spawner with an emission rate, it should have a fixed number of enemies it can spawn (and potentially reuse them after they’re dead).
Potentially Wasted Space
If you allocate enough data for the worst case in your game, that can lead to a lot of unused data most of the time. That’s only an issue if that unused data is preventing you from adding more content to the game. We might initially balk at the idea of having 2000 preallocated enemies when we’re only going to see 10 of them at once. But when you realize that each of those enemies is only taking 256 bytes and the total overhead is 500 KB, which can be easily accommodated in most modern platforms today.
Preallocation doesn’t have to be as draconian as it sounds though. You could relax this approach and commit to having each level preallocated and never having dynamic memory allocations while the game is running. That still allows you to dynamically allocate the memory needed for each level and keep wasted space to a minimum. Or you can take it even further and preallocate the contents of memory blocks that are streamed in memory. That way each block can be divided in the best way for that content and wasted space is kept to a minimum.
Reuse, RecycleM
If you don’t want to preallocate every single object you’ll ever use, then you can create a smaller set, and reuse them as needed. This can be a bit tricky though. First of all, it needs to be very much specific to the type of object that is reused. So particles are easy to reuse (just drop the oldest one, or the ones not in view), but might be harder with enemy units or active projectiles. It’s going to take some game knowledge of those objects to decide which ones to reuse and how to do it.
It also means that systems need to be prepared to either fail an allocation (if your current set of objects is full and you don’t want to reuse an existing one), or they need to cope with an object disappearing from one frame to another. That’s a relatively easy problem to solve by using handles or other weak references instead of direct pointers.
Then there’s the issue that reusing an object isn’t as simple as constructing a new one. You really need to make sure that when you reuse it, there’s nothing left from the object it replaced. This is easy when your objects are just plain data in a table, but can be more complicated when they’re complex C++ classes tied together with pointers. In any case, you can’t apply the Resource Acquisition Is Initialization (RAII) pattern, but it doesn’t seem to be a pattern very well suited for games, and it’s a small price to pay for the simplicity that preallocation provides.
Specialized Heaps
Truth be told, a pure pre-allocated approach can be hard to pull off, especially with highly dynamic environments or games with user-created content. Specialized heaps is a combination of dynamic memory allocation and pre-allocation that takes the best of both worlds.
The idea behind specialized heaps is that the heaps themselves are pre-allocated, but they allow some form of specialized dynamic allocation within them. That way you avoid the problems of running out of memory, or memory fragmentation globally, but you still can perform some sort of dynamic allocation when needed.
One type of specialized heaps is based on the object type. If you can guarantee that all objects allocated in that heap are going to be of the same size, or at least a multiple of a certain size, memory management becomes much easier and less error prone, and removes a lot of the complexity of a general memory manager.
My favorite approach for games is to create specialized heaps based on the lifetime of the objects allocated in them. These heaps use sequential allocators, always allocating memory from the beginning of a memory block. When the lifetime of the objects is up, the heap is reset and allocations can start from the beginning again. The use of a simple sequential allocator bypasses all the insidious problems of general memory management: fragmentation, compaction, leaks, etc. See the code in http://gdmag.com/resources/code.htm for an implementation of a SequentialAllocator class.
The heap types most often used in games are:
- Level heap. Here you allocate all the assets and data for the level at load time. When the level is unloaded, all objects are destroyed at once. If your game makes heavy use of streaming, this can be a streaming block instead of a full level.
- Frame heap. Any temporary objects that only need to last a frame or less get allocated here, and destroyed at the end of the frame.
- Stack heap. This one is a bit different from the others. Like the other heaps, it uses a sequential allocator and objects are allocated from the beginning, but instead of destroying all objects at once, it only destroys objects up to the marker that is popped fro the stack.
What About Tools?
You can take everything I’ve written here, and (almost) completely ignore it for tools. I fall in the camp of the programmers who consider the runtime as a totally separate beast from the tools. That means that the runtime can be lean and mean and minimalistic, but I can relax and use whatever technique makes me more productive when writing tools. That means you can allocate memory any time you want, you can use complex libraries like STL and Boost, etc. Most tools are going to run on a beefy PC and a few extra allocations here and there won’t make any difference.
Be careful with performance-sensitive tools though. Tools that build assets or compute complex lighting calculations might be a bottleneck in the build process. In that case, performance becomes crucial again and you might want to be a bit more careful about memory layout and cache coherency.
On the other hand, if the tool you’re writing is not performance sensitive, you should ask yourself if it really needs to be written in C++. Maybe C# or Python are better languages if all you’re doing is transforming XML files or verifying that a file format is correct. Trading performance for ease of development is almost always a win with development tools.
Next time you reach out for a malloc inside your main loop, think about how it can fail. Maybe you can pre-allocate that memory and stop worrying about what’s going to happen the day you prepare the release candidate.
This article was originally printed in the February 2009 issue of Game Developer.
Life In The Top 100 And The Google App Engine
A few weeks ago I wrote about using the Google App Engine as a back end for Flower Garden. One of the comments I heard from several people is that the Google App Engine pricing scheme is “scary” due to its unpredictability. What if your server gets very busy and you find yourself with a huge bill?
Google App Engine Costs
At the time I wrote that post, the bandwidth of Flower Garden (and Flower Garden Free) was just under the free bandwidth allowance, so I didn’t have to pay anything. However, this last week, after riding the Pocket Frogs rocket, Flower Garden Free shot up to the #56 overall app in the US. And boy, did that make a difference in server usage!
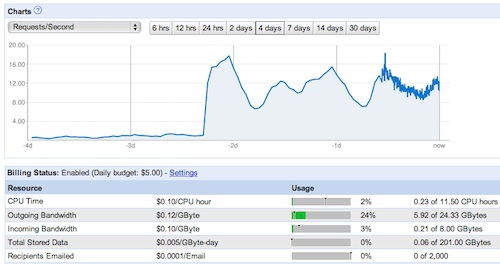
That screenshot shows the Google App Engine dashboard with the number of requests per second for a 4 day period. Can you guess when the Pocket Frogs cross-promotion started? It went from an average of 1.5 requests per second, to a peak of about 16. That’s a factor of 10 right there.
Let’s see what that means in terms of cost. With the Google App Engine, you get charged for different resources you consume: CPU usage, incoming bandwidth, outgoing bandwidth, data storage, and recipients emailed. Of those, the only one that Flower Garden makes any dent on is outgoing bandwidth (mostly the HTML pages and images in the Flower Shop).
For each of those resources, you get a free amount every day. In the case of outgoing bandwidth, we get 1GB before we have to start paying anything. Afterwards, it’s $0.12 per GB. The peak day for Flower Garden Free, when it was all the way at #56, it consumed 7.8 GB. Now that it’s back down, it’s using up at around 2-3 GB of outgoing data every day.
That means, that the busiest day I was charged $0.82 in bandwidth, but the profits for that day were over $1500! I can only hope for days just as busy!

As a reference, these are my Google App Engine charges for the busy week during the promotion. $3.28 for the week? Bring it on! 🙂
Minimizing Bandwidth
When I first saw the first day’s bandwidth, I was pretty surprised it was taking up that much. I hadn’t tried to minimize it first, but 8 GB seemed like a significant amount.
The first thing I did was to forward any requests to the “More Games” and “News” section back to the Dreamhost account. After all, if that server goes down, it doesn’t really matter, and they can take up significant bandwidth with all the images.
To forward something, I couldn’t just do it from the configuration file. Instead, I set a handler for the moregames directory like this:
- url: /moregames/.* script: redirect.py
And the redirect script is very simple:
import os import sys import logging from google.appengine.ext import webapp from google.appengine.ext.webapp.util import run_wsgi_app class RedirectMoreGames(webapp.RequestHandler): def get(self, params): url = "http://flowers.snappytouch.com/moregames/Snappy_Touch_More_Games/More_Games.html" self.redirect(url, permanent=True) application = webapp.WSGIApplication( [(r'/(.*)', RedirectMoreGames), ], debug=True) def main(): run_wsgi_app(application) if __name__ == "__main__": main()
Another thing you can do is to turn on explicit caching of files in the app.yaml file for your Google App Engine app. I don’t know how much that helps with data requested from within an iPhone app, but it can’t hurt.
Finally, I made some changes to Flower Garden. I never had bandwidth minimization in mind, so for example, I was happily requesting updated news and other data at the beginning of every session. I wised up a bit and now it only requests that data at most once every few hours or days.
In case you’re ever getting close to using up your quotas, I learned that you can query them at runtime. I haven’t done anything about it yet, but I suppose I could start forwarding image fetches to a backup server whenever I get close to the limit. But for that, I’ll have to sell many more units of Flower Garden!
Google App Engine Shortcomings
Overall, I’m very happy with the Google App Engine. But it’s not all a bed of roses over here. I think the Google App Engine excels at scaling under heavy load, but surprisingly, it doesn’t have anything close to 100% uptime. I’m going to say it probably doesn’t even have 95% uptime! With such a massive system and all the redundancy underneath, I’m surprised they can’t have better uptime. Supposedly their status page makes you think everything is perfect, but it’s really far from it.
Apart from downtime, people are also reporting severe latency issues sometimes, and I’ve seen some errors like that in my log every so often. Chalk it up to being a beta I suppose. I imagine it’s only going to get better with time.
I would still use the Google App Engine for any new game I’ll release in the future, whether it has big or small backend needs. If nothing else, the ease of development and testing beats every alternative for me.
This post is part of iDevBlogADay, a group of indie iPhone development blogs featuring two posts per day. You can keep up with iDevBlogADay through the web site, RSS feed, or Twitter.