Up until a few weeks ago, I never had any problems with iPhone game resources. I just added whatever I needed to the XCode project, and it was ready to load from within the game. That simple.
But that was because of the kind of games I was making, which were very light on content, with mostly procedurally generated assets (the consequence of working by myself and being much better at programming than at Photoshop).
That game that Miguel and I are working on right now is a lot heavier on assets. It has locations, and levels, and the whole shebang. And that’s where XCode starts falling short.
Explicit Resources
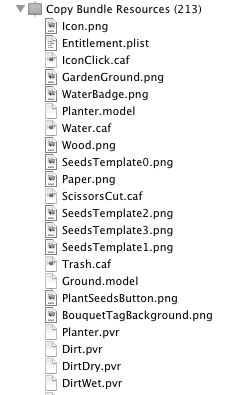 Before, I was adding all my game assets to the Resources folder in XCode. That adds the file to the “Copy Bundle Resources” step. And as you expect, when you do a build, it checks the date of the existing file, and only copies it if the source file is newer than the destination file.
Before, I was adding all my game assets to the Resources folder in XCode. That adds the file to the “Copy Bundle Resources” step. And as you expect, when you do a build, it checks the date of the existing file, and only copies it if the source file is newer than the destination file.
Personally, I really like this approach. I like to be explicit about what gets included in a game, and I don’t mind at all having to add files manually to the project.
Unfortunately, it has one major flaw: It collapses all assets at the root of the application directory, ignoring the directory structure where they came from. I have no idea what the rational is for this “feature”, but someone needs to be taken out to the public town plaza and whipped for that. Actually, make that a double-whipping session if the reason was “convenience”.
The reason this becomes a big deal now is that we have per-level resources. To keep things sane, we decided to use a directory hierarchy, so Levels/Level00 contains all the files necessary for that level. Same thing with Level01, etc. The problem comes that both those levels have similarly named files: Background.jpg Layout.bin, etc.
Any guesses what happens if you add to XCode two files with the same filename in different paths? Yup. One of them overrides the other. Not a single warning either. Let’s make that a triple-serving of whipping, please.
I briefly considered prefixing all the files with the level name (Level00_Background.jpg), but if later I decide to move Level00 to Level05 that’s a lot of files to rename, so I would end up having to write scripts, or create a separate file with the level ordering, or just generally waste my time doing something that should have been taken care of by the tool.
Folder References
Even though I had read they had their share of problems, I decided to look a folder references (at Miguel’s prompting mostly).
When you add some resources to XCode, you have an option to check “Create Folder References for any added folders”. That option automatically adds any files in those folders without having to explicitly add them to XCode. So you could add the Levels folder, and then any files you create there will be copied with the game.
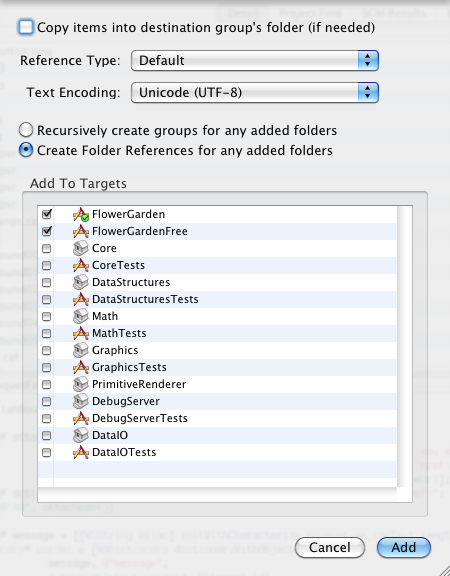
I’m not a big fan of assets copied automatically, but as a side effect, that step preserves the directory hierarchy each of those files was in. So any files copied this way can be accessed from within the game by using their full directory structure.
I have to ask again: Why are directory structures preserved here but not with explicit resources added to the project? The mind boggles.
But hey, at least it works, right? Not exactly. There are a couple of gotchas.
The big one I had read in multiple places, is that XCode doesn’t detect any changes to files inside the referenced folder. So you can be making all sorts of changes, building the game, and not seeing anything different. The recommended solution was to add an extra step to the build process that would start by touching the reference folder, forcing a full copy of all assets.
I tested that, I’m glad to report that at least in XCode 3.2.4, that’s not the case. If you modify any file inside a referenced folder, the file will get copied over correctly during the build process without the need of extra steps.
The bad news is that all the files in the referenced folder will be copied. Why oh why??? They clearly know which file changed, why do they feel the need to copy all of the other files? No idea. This is not a big deal early on, but as you start to accumulate dozens and hundreds of megabytes of assets, build times start increasing quite a bit, especially on the device itself.
This is what the copy command looks like for referenced folders:
CpResource build/Debug-iphonesimulator/Test.app/Levels Levels cd /Users/noel/Development/Test/trunk/Test setenv PATH "/Developer/Platforms/iPhoneSimulator.platform/Developer/usr/bin:/Developer/usr/bin:/usr/bin:/bin:/usr/sbin:/sbin" /Developer/Library/PrivateFrameworks/DevToolsCore.framework/Resources/pbxcp -exclude .DS_Store -exclude CVS -exclude .svn -Testve-src-symlinks /Users/noel/Development/Test/trunk/Test/Levels /Users/noel/Development/Test/trunk/Test/build/Debug-iphonesimulator/Test.app
It’s nice touch that it automatically excludes .svn directories though. I was wondering why they use CpResource instead of plain, old cp, but I guess that’s to be able to -exclude specific files. Fair enough.
However, what CpResource apparently doesn’t do is to process any of the resources in ways that were processed before by XCode. For example, a png file would have been processed by premultiplying it and byte swapping it so loading it in the iPhone would be slightly more efficient. CpResource just does a regular copy and leaves it alone. So if you were relying on that behavior, you need to do it explicitly yourself in your asset baking step.
What I Really Want
For now, I’m using folder references for the levels, and explicit references for everything else. That way I keep the data size to a minimum but I get to have the directory hierarchy. Not ideal, but at least it works.
This is what I would really like thought:
- Easiest: Explicit assets with paths. I really want to just add resources to XCode and have it preserve the directory structure. It’s not that hard. If XCode were open source, I would have made that change a long time ago. Can we at least have this as an option?
- Second easiest: Folder references that only copy the changed resources. That would also be OK in my book, and I can’t believe it would be much harder to implement either.
- Best: A remote file system hosted on the Mac during debug build. All file references go out to the host machine and get loaded on the fly. This would allow for fastest build times and loading times would not be that different from a fragmented drive on an old device probably. I know some of you already have something like this. Has anybody made one open source (preferably minimalistic and standalone)? I’d love to check it out.
Of course, all of this has probably changed already with XCode 4, but I’m deathly afraid of installing it while working on a production game. Has anybody tried it yet? Have they fixed anything, or is it even more broken?
To wrap things up, and since Miguel is spilling the beans on Twitter, I’ll share a few assets from our current game. Now back to the game because we’re submitting it to the Independent Games Festival on Monday. Next Thursday I’ll talk about the IGF. Wish us luck!

This post is part of iDevBlogADay, a group of indie iPhone development blogs featuring two posts per day. You can keep up with iDevBlogADay through the web site, RSS feed, or Twitter.
 So
So  Development tools and hardware have changed quite a bit from the times I was writing in
Development tools and hardware have changed quite a bit from the times I was writing in 
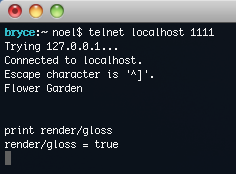 Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.
Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.