Writing Reusable Code
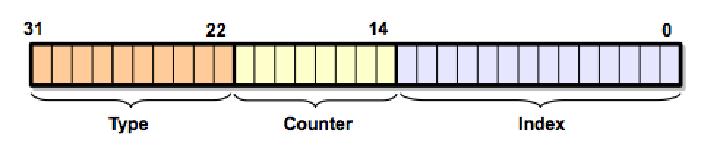
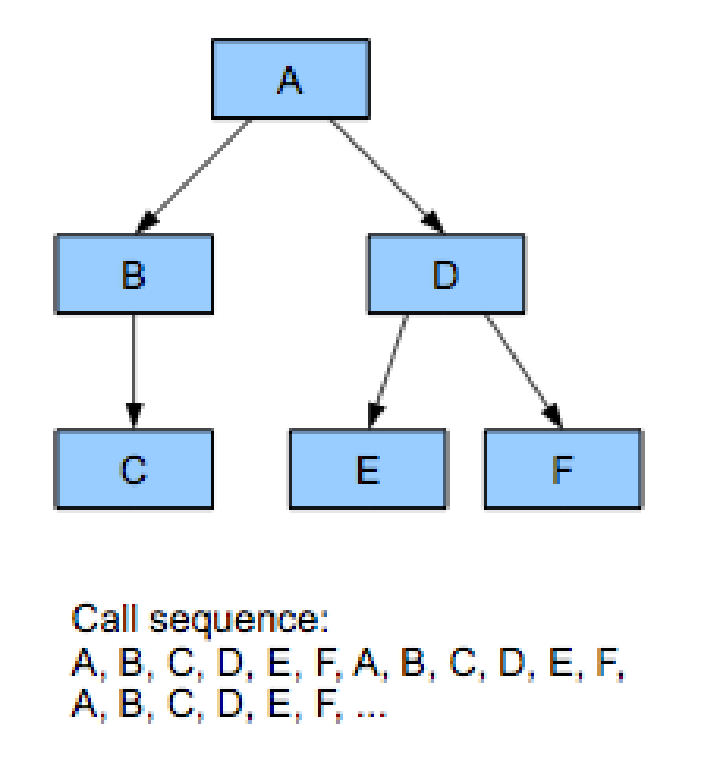
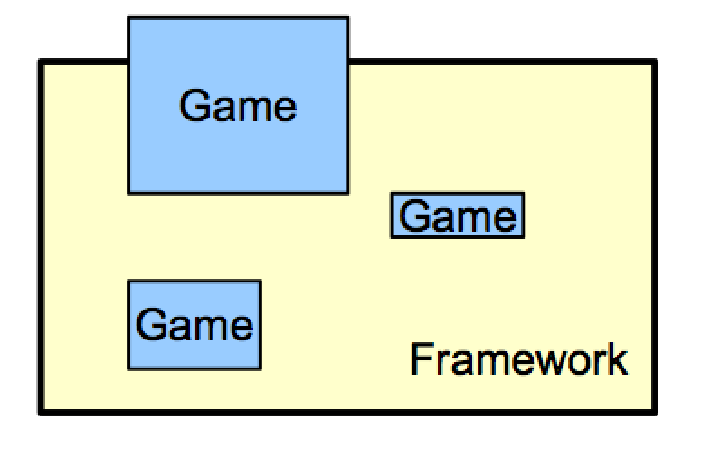
Some people asked what I meant by a “toolkit architecture” in the previous post about my middleware fears. It turns out I wrote about that in a previous Inner Product column that for some reason I never reposted here. I think at the time I wrote this (late 2008), I already wasn’t very concerned about writing reusable code, and I was focusing it mostly with respect to using other people’s code and how I wanted it to be architected. ...