Update (Apr 2010): It’s been quite a few years since I originally did this comparison. Since then, Charles Nicholson and I created Unit Test++, a C/C++ unit-testing framework that addresses most of my requirements and wish-list items. It’s designed to be a light-weight, high-performance testing framework, particularly aimed at games and odd platforms with limited functionality. It’s definitely my framework of choice and I haven’t looked at new ones in several years because it fits my needs so well. I definitely encourage you to check it out.
-———
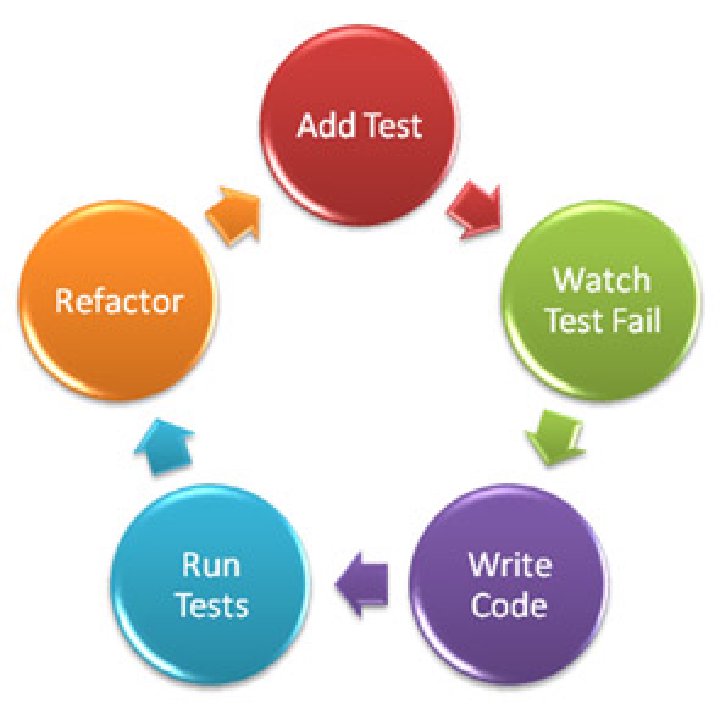
One of the topics I’ve been meaning to get to for quite a while is the applicability of test-driven development in games. Every time the topic comes up in conversations or mailing lists, everybody is always very curious about it and they immediately want to know more. I will get to that soon. I promise!
In the meanwhile I’m now in the situation that I need to choose a unit-testing framework to roll out for my team at work. So, before I get to talk about how to use test-driven development in games, or the value of unit testing, or anything like that, we dive deep into a detailed comparison of existing C++ unit-testing frameworks. Hang on tight. It’s going to be a long and bumpy ride with a plot twist at the end.
...