Some people asked what I meant by a “toolkit architecture” in the previous post about my middleware fears. It turns out I wrote about that in a previous Inner Product column that for some reason I never reposted here. I think at the time I wrote this (late 2008), I already wasn’t very concerned about writing reusable code, and I was focusing it mostly with respect to using other people’s code and how I wanted it to be architected.
As programmers, we’re constantly reusing code. Sometimes it’s in the form of low-level OS function calls, or game middleware, and sometimes code that our teammates wrote. At the same time, unless you’re writing top-level game script code, chances are that the code you’re writing will be used by people as well.
I’m purposefully avoiding labeling reusable code as “libraries” or “middleware”. Those are just two of the many forms in which we end up reusing code. Copying some source files onto your project, calling an API function, or instantiating a class written by someone else in your team, are all different forms of code reuse.
Getting Started
Without a doubt, the most difficult job writing reusable code, is making sure it solves a problem correctly and meets everybody’s needs. That’s not a easy task when we’re writing code for ourselves, but it’s much more difficult when we’re targeting other programmers. Too many libraries get it only half right, and they solve some problems at the expense of introducing a bunch of new ones. Or they force the user to jump through all sorts of hoops to get the desired result in the end. We need a clear understand of the exact problem we’re trying to solve with our code.
Libraries often fall in the trap of presenting an implementation-centric interface. That is, their interface is based on the implementation details of the library, rather than how the users are going to use it in their programs.
The best way I’ve found to address both those shortcomings is to start by implementing code that solves the problem for one person. Just one. Forget about multiple users and code reusability for now. If you don’t have immediate and constant access to that one person, then you need to play that role and create a game or application that is as close as possible to what one of your users is going to be developing. By using this approach, I find that the interface to the reused code is much more natural, and it’s based on the experience of having solved the problem at least once. Otherwise, you run the risk of creating an interface that is not a good fit and forcing everything to conform to it in unnatural ways.
Once you have implemented a solution, take a moment to think before you dive into doing any more work. Many times you’ll find there is no reason to abstract it any further since your code is only going to be used in one place. If that’s the case, step away from the code and go do something more productive. You can always come back later whenever there is a real need to reuse it later in the project or in a future game.
There are exceptions to this approach of implementing a solution first, and abstracting it later. Some problems are very simple, or very well understood, so we might be able to jump in and implement the reusable solution directly (an optimized search algorithm, or a compression function for example). It’s also possible that you’ve implemented a similar system several times before, and you know exactly at what kind of level to expose the interface and how things should look like. In that case, it’s perfectly valid to draw on your past experience. Just try to avoid the second-system effect: The tendency to follow up a successful, simple first system, by an overly-complex system with all the ideas that didn’t make it into the first one.
Setting Goals
Most successful reusable code was created with specific goals about how it was meant to be used. Sometimes those goals are explicitly stated, most of the time they are implied in the code design.
Some of the most common goals are flexibility, protection, simplicity, robustness, or performance. You can obviously not meet all those goals at once, and even if you could, you probably shouldn’t try. That would be a tremendous waste of time and resources. Stop thinking in the abstract and think about your one user. What does he or she need? What is the most important goal for them?
Many APIs and middleware packages are designed with protection as one of the primary goals: They don’t want the user to accidentally do anything wrong. In itself is not a bad goal, and it can often be implemented by having clean, unambiguous interfaces, clearly-named types and functions, and strongly-typed data types. Unfortunately, a design with protection as a main goal can often result in encumbered interfaces, verbose code, slow performance, and inflexible code. There is nothing more frustrating than wanting to do something that is explicitly being protected against, and having to work around the interface.
If your target users are professional game developers, give them the benefit of the doubt and don’t try to overprotect all your code. Save that for the scripting API exposed to junior designers and released to the customers with the game. If you’re concerned about programmers using your code correctly and not making mistakes, provide good sample code, tests, and documentation. If that’s not enough, and you feel that everybody would benefit from some level of protection, try to keep it to a minimum and maybe even provide lower-level functions that bypass it for power users.
Whatever the primary goal, the libraries and APIs I prefer to work with, help me get whatever I need done, while getting out of the way as much as possible.
Architecture
There are many different ways to architect code that is intended for reuse. The best approach will depend on the particular code: How complex is it? How much of it is there? What are its goals?
Unless your goals are to make quick, throwaway applications, I strongly recommend against a framework type of architecture (see Figure 1.) A framework is a system in which you add a few bits of functionality to customize your program into an existing system. They may sound like a clean and easy way to use complex code, but they’re inevitably very restrictive, and they make it very difficult, if not impossible, to do things with them beyond what they were intended to.
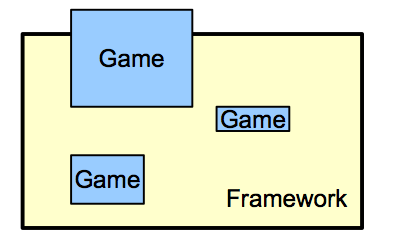
A more flexible approach is a layered architecture (see Figure 2.) Each layer is relatively simple and provides a well-defined set of functionality. Higher-level layers build on top of lower-level layers to create more complex or more specific functionality.
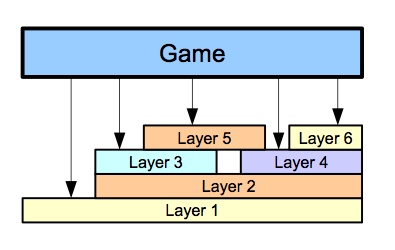
Keep in mind that it is not necessary, or even desirable, to have higher-level layers completely abstract out and hide the lower-level ones. By letting layers be fully transparent, they allow you to mix and match at what level you want to access the code. This can be very important, especially towards the end of a game when fixing some bugs or trying to squeeze some more performance out of the engine.
For example, one layer can expose functionality to create and manipulate pathfinding networks and nodes, another one can implement searches and other queries on those networks, while a third, higher-level layer, can expose functions to reason on the state of the network.
A toolkit architecture (see Figure 3), is the most flexible of all. It provides small, well-defined modules or functions with very few dependencies on other modules. This allows users to pull in whatever modules they need into their game to meet their needs and nothing else. Users can also start by reusing some modules, and but replace them down the line when they want to go beyond the existing functionality. Because of this, toolkit architectures are particularly well suited to game development.
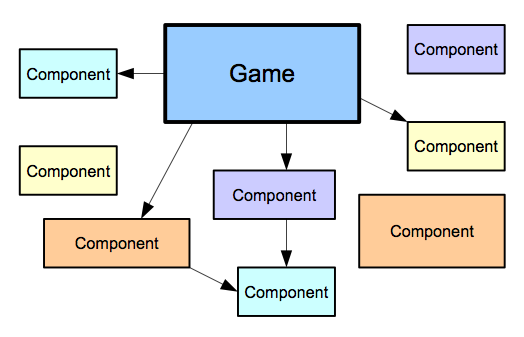
Object Oriented
I tend to avoid complex class hierarchies in most of my code, but that’s especially important in the case of reusable code. Class hierarchies are very rigid, and impose a particular structure on their users.
If you want to remain object-oriented, a better approach is to emphasize composition of objects instead of inheritance. That allows users to much more easily pull in the functionality they need, and create their own objects based on their own constraints.
You can even go a step further and provide purely procedural interfaces. Plain static functions that operate on data types. Interfaces based on static functions are often much easier to understand and grasp than interfaces that involve classes and inheritance. They are also much more convenient for users to wrap and use in many different ways.
Remember what you learned about object-oriented design and having private data? Forget about it, and keep everything accessible. You may think you’re doing the user a favor by making some variables private and reducing the complexity of the interface. That’s partly true, but eventually, your users will want to have access to some of those variables that you took pains to hide. And if they really want to, they will get to them, even if it means direct addressing into an object or vtable.
It’s true that large codebases can be intimidating, and exposing all the internal details along with the regular interface would make it unwieldy for new users. An effective approach is to separate the public interface from what is intended for internal use only, but still make it available through some other means. For example, private data and functions could be wrapped in a different namespace, or simply in a different set of headers. Anything that clearly sets them apart, and doesn’t clutter the initial look at the interface, but that allows experienced developers to get to them and get their hands dirty.
Extensibility
As soon as you make your code available to a wide range of developers, you’ll find that people want to use it in progressively more complex and bizarre situations. Your code might have completely solved the case of your first couple of users, and since it’s layered and modular, it can meet a lot of different requirements. But eventually, some people will start taking it to extremes you hadn’t imagined and it falls short for them. What to do?
You could start adding more options and more modules and more callbacks to your code. That way programmers can hook up into almost any part of the code and replace it with their own. The problem with that approach is that you’ve taken something that was relatively simple and made it into an large, ugly, fully-customizable, behemoth that tries to keep everybody happy. That sounds like a lot of common APIs we know and hate. Most successful products try to completely meet the need of some people rather than meet everybody’s needs part way. Otherwise you inconvenience 95% of your users for the benefit of 5% of them.
A better approach is to let those 5% users fend for themselves, but give them the means to do it. How so? With source code. Without source code, developers feel caged and constrained. They know they can’t look behind the interfaces, let alone modify anything in case something goes wrong (and we all know something will go wrong). The more code there is, and the more a project relies on it, the more important it is to have access to the full source code. Many teams will refuse to use some libraries or middleware unless the full source code is available. As soon as you make source code available to your users, you immediately put them more at ease because they feel more in control, and you allow those with special requirements to make whatever modifications they need to do.
Even those developers without a need to modify the code, they will be able to browse the code and see how certain functions are implemented. Not only will it make people much more likely to use your code, but they will probably also fix your bugs and suggest performance improvements, so it’s a win-win situation for everybody.
For extra bonus points, the source code should be accompanied by a set of tests. The more comprehensive the better (unit tests, functional tests, etc). Hopefully you created all those tests while you were developing the code, so distributing it along with the source code shouldn’t be any extra effort, but it will make a huge difference to your users. It will give them much more confidence modifying the code to suit their needs and still see that all the tests are passing.
Upgrades
As soon as you release some code and you have your first user, the question comes up of how to deal with new versions. There are many ways you can go about it, depending on how often you’ll release new versions, and how important it is to maintain backwards compatibility.
On one extreme, you can change the code and the interface to fit new features, changes in architecture, or any other reason. Whenever you release a new version, users will have to choose to remain with their current version or upgrade to the latest and make whatever changes are necessary. This is a common approach in open source projects and internal company code.
On the other extreme, once you release a version, you stick to that interface whether it’s a good idea or not. This can be good for users because they can get new versions without any extra work on their part, but it can be very constraining. It can make new features impossible to add, and it can prevent performance optimizations. This approach is more common on code that will become the foundation of many programs, like OS libraries and low-level APIs.
A good compromise is to keep interfaces the same during minor versions, and only change them whenever a major version is released. That way other developers only have to put in the time to upgrade to a major release if they really need the new features at that time.
Another approach is not to change existing functions or classes, but to introduce new ones and slowly deprecate the old ones over time. That way code continues to work, but users can take advantage of the new functions. After a few versions, you can completely drop off deprecated functionality, at which point most people will have upgraded already. If you do this, make sure to label deprecated functions with a #pragma warning or some other way. That way, developers know it will be phased out and they can start thinking about upgrading to the new interface.
The easier you make the transition to the new version, the better for your users, and the more likely they will be continue using your code. For example, you can provide scripts that parse their source code and upgrade it to match the new interfaces. That can be a bit risky, but it can be really worthwhile if you have a lot of required changes that are relatively mechanical (renamed functions, changed parameter order, etc).
Is there any point to all this talk of interfaces if you made your source code available? Yes, very much so. Most developers will look at the source code to know how things work under the hood, but they probably won’t modify it. Even if they do, they know that’s something they do at their own risk, so they’ll be more than willing to make a few changes whenever a new version is released. Everybody else will still definitely benefit from a relatively stable interface.
Conclusion
Writing reusable code starts with solving a problem and solving it well. The rest should all fall from there, and you can pick whichever method is more appropriate for your particular code and how you want to share it.
This article was originally printed in the March 2009 issue of Game Developer.
No. No. No. Don’t design for “reuse”, design for “use”. Don’t write “reusable” code, write “usable” code. http://www.two-sdg.demon.co.uk/curbralan/papers/minimalism/TheImperialClothingCrisis.html
I agree. This is just intended for people who are forced to write reusable code like middleware providers. I just write code and skip the reusable part 🙂
Middleware providers should write code for use too. (reuse is a silly word)
I remember reading this in 09, Far Cry on the cover I think. Great re-read given the previous blog topic.
An Anecdote
One of the first things I worked on at my current day job was a dynamic library/module that marshaled out business logic to different portions of a large complex information system. We used the layer approach and it worked well initially. Now that module is at a size where we look back and second guess our selves weekly. It is feature creep that has bloated the module. Lots of the consumers of the module want there business service to be additional parts of the core module. These additions were never designed as part of the library. Given the “current” user requirement the component approach would have allowed for more flexibility.
Point being is coding reusability is a b!tch.
In my game dev stuff I’ll use others apis for rendering and physics but I have made a point to not think about whether I can reuse any of my game logic. When I start thinking reuse I log off and go play with the kids. IMHO, thinking reuse is not conducive to getting any real product out the door…