Lag in games is as inevitable as taxes. It’s something we can try to minimize, but we always need to live with it. Earlier this week, I noticed that input for my new iPad game was very laggy. Excessively so, to the point it was really detracting from the game, so I decided I had to look into it a bit more.
Lag In Games
 I’m defining lag as the time elapsed between the moment the player performs an input action (press a button, touch the screen, move his finger), until the game provides some feedback for that input (movement, flash behind a button, sound effect).
I’m defining lag as the time elapsed between the moment the player performs an input action (press a button, touch the screen, move his finger), until the game provides some feedback for that input (movement, flash behind a button, sound effect).
Mick West wrote a great article on the causes of lag in games, followed up by another one in how to measure it. I’m going to apply some of that to the lag I was experiencing in my game.
Lag can be introduced in games by many different factors:
- Delay between gathering input and delivering it to the game.
- Delay rendering simulation state.
- Delay displaying the latest rendered state on screen.
The new game runs on the iPad and involves moving objects around the screen with your finger. To make sure it wasn’t anything weird with the rest of the game code, I wrote a quick (and ugly!) program that draws a square with OpenGL that follows your finger on the screen. When you run the sample, the same lag becomes immediately obvious.
The iPad is a much larger device than the iPhone, and it encourages a physical metaphor even more. As soon as you attempt to move an “object” on screen, the lag kills that sense of physicality. Instead of moving an object around with your finger, you’re dragging it around with a rubber band. It moved the player from applying direct action on screen, to being removed and disassociated with the actions on screen.
Loop Structure
The place to start looking for lag is in my main loop. The main loop looks something like this:
ProcessInput(); UpdateSimulation(); RenderWorld(); PresentRenderBuffer();
So I was reading the input correctly before the simulation. Nothing weird there.
Touch input is delivered to the code as events from the OS. Whenever I received those events (outside of the main loop), I queue them, and then process them all whenever the main loop starts in ProcessInput().
The loop runs at 60Hz, so the lag here is at most 16.7 ms (if you’re running at 30Hz, then you’re looking at a delay up to 33.3ms). Unfortunately, the lag I was seeing in the game was way more than one frame, so there was to be something else.
Rendering
For some reason, I thought that iDevices were triple buffered. I ran some tests and fortunately it looks like it’s regular double buffering. That means that if I render a frame and call presentRenderBuffer(), the results of that render will be visible on screen at the next vertical sync interval. I’m sure there’s a slight lag with the iPad screen, but I’m willing to be is close to negligible when we’re talking about milliseconds, so we’ll call that zero.
Main Loop Calls
The game uses CADisplayLink with interval of 1, so the main loop is called once every 16.7 ms (give or take a fraction of ms). I thought that perhaps CADisplayLink wasn’t playing well with touch events, so I tried switching to NSTimer, and even to my old thread-driven main loop, but none of it seemed to make any difference. Lag was alive and well as always.
That the simulation and rendering in the game are very fast, probably just a few ms. That means the rest of the system has plenty of time to process events. If I had a full main loop, maybe one of the two other approaches would have made a difference.
It looks like the lag source had to be further upstream.
Input Processing
On the dashboard, press and hold on an icon, now move it around the screen. That’s the same kind of lag we have in the sample program! That’s not encouraging.
A touch screen works as a big matrix of touch sensors. The Apple OS processes that input grid and tries to make sense out of it by figuring out where the touches are. The iOS functions eventually process that grid, and send our programs the familiar touchesBegan, touchesMoved, etc events. That’s not easy task by any means. It’s certainly not like processing mouse input, which is discrete and very clearly defined. For example, you can put your whole palm down on the screen. Where are the touches exactly?
TouchesBegan is actually a reasonably easy one. That’s why you see very little lag associated with that one. Sensors go from having no touch values, to going over a certain threshold. I’m sure that as soon as one or two of them cross that threshold, the OS identifies that as a touch and sends up the began event.
TouchesMoved is a lot more problematic. What constitutes a touch moving? You need to detect the area in the sensor grid that is activated, and you need to detect a pattern of movement and find out a new center for it. In order to do that, you’ll need several samples and a fair amount of CPU cycles to perform some kind of signal processing on the inputs. That extra CPU usage is probably the reason why some games get choppier as soon as you touch the screen.
Measuring Lag
Measuring lag in a game is tricky. You usually can’t measure it from within the code, so you need to resort to external means like Mick did in his tests.
I decided to do something similar. I pulled out my digital video camera, and started recording my finger moving on the screen. The quality leaves much to be desired, but it’s good enough for the job. I can see how far my finger gets from the center of the square, but that’s not enough information to quantify the lag. How fast is my finger moving exactly? Fortunately, that’s something I can answer in code, so I added that information to the screen [1]. Now, for a given frame, I can see both how far the finger is from the center of the square and how fast it’s going.

The square is 100 pixels wide. When I move my finger at about 500 pixels per second, the center of my finger is on the edge of the square. That makes a rough 100 ms total delay from input until it’s rendered. That’s a whopping 6 full frames at 60 fps!
What Can We Do About It
As iOS developers, there isn’t much we can do. Make sure your loops are set up correctly to avoid an extra frame delay. Make sure you provide feedback as soon as you can and don’t delay it any longer than you have to. Other than that, there’s nothing much we can do.
I’ve been saying this for a while, but I’m a big fan of layers as long as you can get to the underlying layers when you need to. Here’s a perfect case where it would be fantastic if Apple gave us raw access to the touch matrix input. Apart from being able to process the input faster (because I know what kind of input to expect for the game), can you imagine the possibilities that would open up? Input wouldn’t be limited to touch events, and we could even sense how “hard” the user is pushing, or the shape of the push.
At the very least, it would be very useful if we had the option to allocate extra CPU cycles to input recognition. I’m not doing much in my game while this is going on, so I’d happily give the input recognition code 95% of the frame time if it means it can give me those events in half the time.
I’m hoping that in a not very far distant, iDevices come with multiple cores, and maybe one of those cores is dedicated to the OS and to do input recognition without affecting the game. Or maybe, since that’s such a specialized, data-intensive task, some custom hardware could do the job much faster.
Until then, we’ll just have to deal with massive input lag.
How about you? Do you have some technique that can reduce the touch event lag?
LagTest source code. Released under the MIT License, yadda, yadda, yadda…
[1] I actually shrank the OpenGL view to make sure the label wasn’t on top if it because I was getting choppier input than usual. Even moving it there caused some choppiness. This is exactly what I saw last year with OpenGL performance dropping when a label is updated every frame!
This post is part of iDevBlogADay, a group of indie iPhone development blogs featuring two posts per day. You can keep up with iDevBlogADay through the web site, RSS feed, or Twitter.
 Even though I was pretty much completely new to the Google App Engine (I had looked into it briefly before the launch of Flower Garden but dismissed it because they couldn’t support the amount of email traffic I needed), it took me two days to port over everything. Actually flipping the switch from the old system to the new one took a while longer, but that required more courage than work. More on that later.
Even though I was pretty much completely new to the Google App Engine (I had looked into it briefly before the launch of Flower Garden but dismissed it because they couldn’t support the amount of email traffic I needed), it took me two days to port over everything. Actually flipping the switch from the old system to the new one took a while longer, but that required more courage than work. More on that later. Every company I’ve ever worked at has done this mistake. The team hashes out a bunch of ideas, and somehow they pick one (or create it by committee). Maybe they’ll create a prototype to show something about the game, or maybe they’ll dive straight and start writing a design document and developing technology. If you’re lucky, or you have an extremely talented game director, the game that comes out of the other end might be fantastic. In most cases, it’s just a so-so idea and the team only realizes it when the first level comes together, years later, at around alpha time. At this point the choice is canning a project after spending millions of dollars, or patching it up to try to salvage something. Neither idea is particularly appealing.
Every company I’ve ever worked at has done this mistake. The team hashes out a bunch of ideas, and somehow they pick one (or create it by committee). Maybe they’ll create a prototype to show something about the game, or maybe they’ll dive straight and start writing a design document and developing technology. If you’re lucky, or you have an extremely talented game director, the game that comes out of the other end might be fantastic. In most cases, it’s just a so-so idea and the team only realizes it when the first level comes together, years later, at around alpha time. At this point the choice is canning a project after spending millions of dollars, or patching it up to try to salvage something. Neither idea is particularly appealing. With a good prototype it’s easy to see if an idea is worthwhile. If it’s not, I discard it and move on to the next one. If it has potential but it’s just so-so, I either choose to continue just a bit longer (to ask another, better question) or I shelve it back in the list of potential game ideas. Maybe at some later time, things might click in or I might have a new inspiration and the game idea might become a lot stronger.
With a good prototype it’s easy to see if an idea is worthwhile. If it’s not, I discard it and move on to the next one. If it has potential but it’s just so-so, I either choose to continue just a bit longer (to ask another, better question) or I shelve it back in the list of potential game ideas. Maybe at some later time, things might click in or I might have a new inspiration and the game idea might become a lot stronger. Also, a good question is concise and can be answered in a fairly unambiguous way. “Is this game awesome?” isn’t a good question because “awesome” is very vague. A better question might be “Can I come up with a tilt control scheme that is responsive and feels good?”. Feels good is a very subjective question, but it’s concrete enough that people can answer that pretty easily after playing your prototype for a bit.
Also, a good question is concise and can be answered in a fairly unambiguous way. “Is this game awesome?” isn’t a good question because “awesome” is very vague. A better question might be “Can I come up with a tilt control scheme that is responsive and feels good?”. Feels good is a very subjective question, but it’s concrete enough that people can answer that pretty easily after playing your prototype for a bit. One of the key concepts in the definition of a prototype was that it has to be fast/cheap (which are two sides of the same coin). What’s fast enough? It depends on the length of the project itself. It’s not the same thing to do a prototype for a two-month iPhone game, than for a three-year console game. Also, a larger, more expensive project probably has more complex questions to answer with a prototype than a simple iPhone game.
One of the key concepts in the definition of a prototype was that it has to be fast/cheap (which are two sides of the same coin). What’s fast enough? It depends on the length of the project itself. It’s not the same thing to do a prototype for a two-month iPhone game, than for a three-year console game. Also, a larger, more expensive project probably has more complex questions to answer with a prototype than a simple iPhone game. When you’re making a prototype, if you ever find yourself working on something that isn’t directly moving your forward, stop right there. As programmers, we have a tendency to try to generalize our code, and make it elegant and be able to handle every situation. We find that an itch terribly hard not scratch, but we need to learn how. It took me many years to realize that it’s not about the code, it’s about the game you ship in the end.
When you’re making a prototype, if you ever find yourself working on something that isn’t directly moving your forward, stop right there. As programmers, we have a tendency to try to generalize our code, and make it elegant and be able to handle every situation. We find that an itch terribly hard not scratch, but we need to learn how. It took me many years to realize that it’s not about the code, it’s about the game you ship in the end.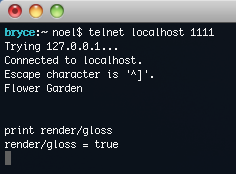 Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.
Because we used the standard telnet protocol, we can start playing with it right away. Launch the game, telnet into the right port, and you can start typing away.